When too much text is too much text, what do I do to get to read it? Why, get a dump of all data 1, throw some automated analysis at it and have the lulz quite guaranteed 2. No better test to see text mining fail, it seems, than applying it to irc logs on bitcoin-assets: a careful calibration of state of the art tools 3 yielded only a clear case of "by the time you figure out and implement everything needed to obtain even reasonable results, you surely did the "automated" work at least 5 times if not 10, if not 100." Not that it was totally unexpected, of course, but still, given the enthusiasm of text mining people (or possibly just that of text mining people I know), I'd have expected at the very minimum some more robust convo splitting and/or term extraction, with a bit of help 4. Not a chance: the results are better even if I split for convos based on the delay between lines (and that's one rough way to do it for sure).
As for extracting key terms, the main result that can be offered is that text mining can find by itself only terms that one has no interest in, or at least not on btc-assets: it did manage to find "BTC" as an important term (go figure) and that was about it all. How terribly useful and incredibly surprising, isn't it? Still, after a bit more fiddling around, it turns out that there is a bit of fun to get out of it. Here's a pretty picture with main "key words" for the logs of May 2014. It makes for good candidate captions such as "never really need to tell," "get one just like bitcoin people" or "mircea_popescu can like just bitcoin people." Real bits of wisdom there, aren't they?

Wordcloud for bitcoin-assets logs from May 2014
Still, data is data and text is no exception, even if spewed forth at incredible rates day and night by a bunch of bitcoiners (and the occasionally lost newbie) on an irc log. Hence, back to more basic tools and trusted numbers, via R. And at least I got some pretty pictures!
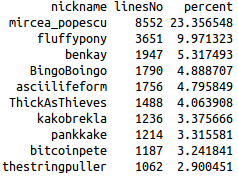
Easiest thing to find out: who's most active? Top 10 contributers (as number of lines rather than number of words) seem to be quite the same, whether it's the whole period considered or just a month. However, the contributions follow (of course) a power law distribution, meaning that there are a few users who contribute a lot to the discussion and many users who contribute very little 5 There is also quite a sharp decline at the top, with mircea_popescu contributing around 20% of the discussion and the next (ThickAsThieves overall or fluffypony in May 2014) barely contributing around 8% and 10% respectively. Here are some charts and lists (I excluded assbot, gribble and ozbot):
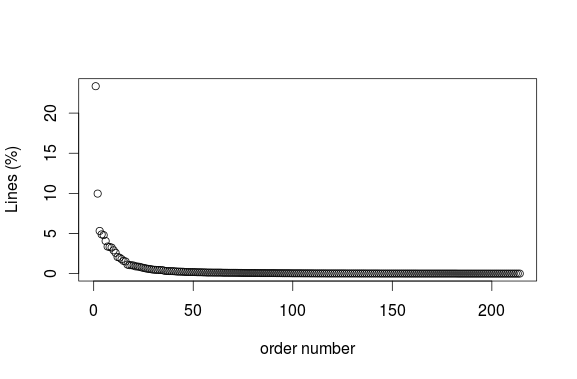 Percentage of lines contributed by distinct nicknames on bitcoin-assets logs between 26 March 2013 and 12 June 2014.
|
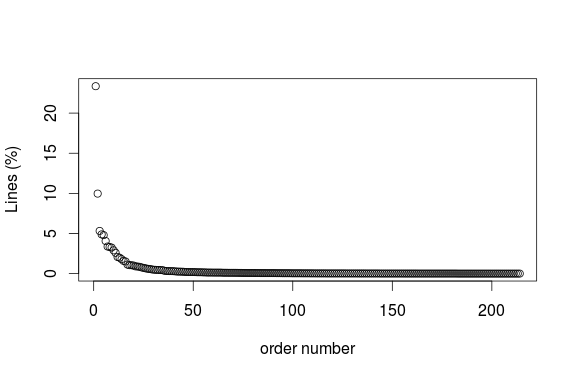 Percentage of lines contributed by individual nicknames on bitcoin-assets in May 2014.
|
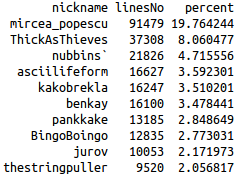 Top 10 contributers on bitcoin-assets between 26 April 2013 and 12 June 2014. |
|
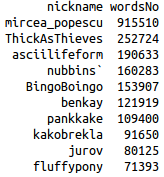 Top 10 contributors overall (total number of words) |
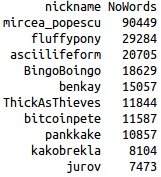 Top 10 contributors in May 2014 (total number of words) |
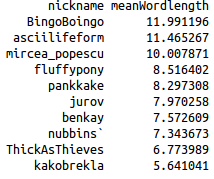 Mean number of words per line for top 10 contributors overall |
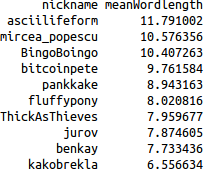 Mean number of words per line for top 10 contributors in May |
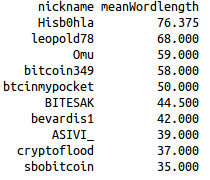 Top 10 overall (mean number of words per line) |
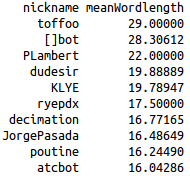 Top 10 in May 2014 (mean number of words per line) |
 Mean number of words per line for top 100 contributors (up to at least 12 words per line) |
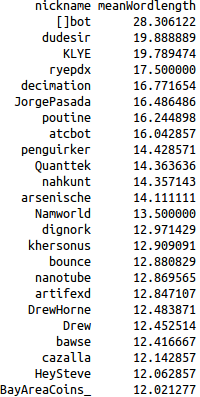 Mean number of words per line for top 100 contributors in May 2014 (limited to those with at least 12 words per line) |
Why is the above interesting? Mainly because it gives the newcomer one reasonable way to start figuring out the whole mess that is otherwise dumped on her head if taking the logs as a whole. Instead of trying to go through all the logs, set a threshold and start by filtering the logs to show first only the contributions of top people, as they are most likely to actually lead the discussions anyway. Considering how fast the percentage of contribution decays, I'd say that taking the first 10 contributors is quite a reasonable option, but for those in a hurry, it will probably do to select even just the first 5. This would reduce the logs effectively by more than half, with minimum chances of truly missing anything really important.
Then again, you could also just hang around in the chan there and the important will not miss you I guess.
- Thanks to kakobrekla.[↩]
- And as a side result, I also get to actually read the logs, which was the point in the first place anyway, as I'd much rather read them for the purpose of designing some kind of tool to extract info out of them in the future than just...you know, read them. But that's just me.[↩]
- think GATE plus all the cool plugins that can be used with it, as well as some custom-made JAPE grammars for the task at hand.[↩]
- To be fair, it probably can be done, but with a TON of help rather than a bit and it kind of defeats the purpose from my point of view right now. Sure, after knowing the logs inside-out and building a good ontology for them and then defining and testing and polishing the rules until they shine, you might be able to get something kind of reasonable from the machine too, but by that time you'd probably get something kind of reasonable on the matter even from your dog.[↩]
- or nothing at all, but I did not count those users here.[↩]
Comments feed: RSS 2.0